人体姿态估计的目标是从给定的图像或视频中确定人的身体关键点(部位/关节)的位置或空间位置。利用深度学习进行姿态估计的方法大致分为两种:自上而下的方法和自下而上的方法。自上而下(top-down),即先检测出来人体,再对单个人进行姿态估计;而自下而上(down-top),则是先检测出人体关节点,再根据检测出来的关节点连成人体骨架。


1.动作识别
追踪一段时间内一个人姿态的变化也可以应用在动作、手势和步态识别上。
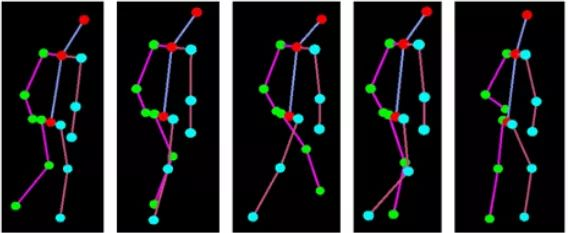
2.运动捕捉和增强现实
人体姿态估计的一个有趣应用是 CGI(computer graphic image)应用。如果可以检测出人体姿态,那么图形、风格、特效增强、设备和艺术造型等就可以被加载在人体上。通过追踪人体姿态的变化,渲染的图形可以在人动的时候“自然”地与人“融合”。

3.训练机器人
除了手动为机器人编程、让它们跟随特定的路径,我们也可以让机器人跟随一个做特定动作的人体骨架。人类教练可以仅通过演示特定的动作,来教机器人学习这一动作。接着,机器人就可以计算如何移动自己的活动关节,来进行相同的动作。
4.控制台中的运动追踪
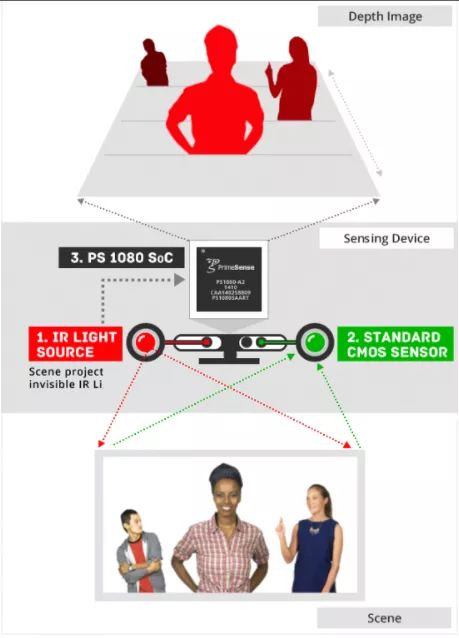
姿态估计的一个有趣应用是在交互游戏中追踪人体对象的运动。比较流行的 Kinect 使用 3D 姿态估计(采用 IR 传感器数据)来追踪人类玩家的运动,从而利用它来渲染虚拟人物的动作。
1.自上而下,先检测人这个整体,再检测出人体关键点。
特点:符合人的思维,先整体后后部分;准确率相对较高。
缺点:推理速度慢。
代表算法:MASK-RCNN, CPN, AlphaPose
2.自下而上,先检测出所有的关键点,再集合成一个人的关键点。
特点:推理速度较快,
缺点:准确率不如自下而上的方法。
代表算法:openpose, DeepCut